



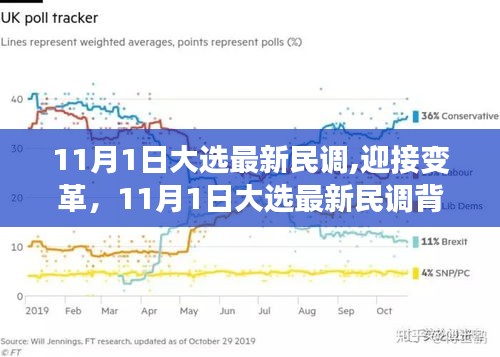

揭秘往年12月18日高效爬取网页数据的秘诀,轻松实现实时更新!

摘要:在往年12月18日,为了实时更新网页数据,采用高效的爬虫技术是关键。通过合理设计爬虫策略,可以轻松实现数据的实时更新。在爬取过程中,需要注意网页的动态变化,选择合适的爬虫框架和工具,以提高数据爬取的速度和准确性。通过这种方式,我们能够快速获取所需数据,为数据分析和应用提供有力支持。
本文目录导读:
开篇引子
随着互联网的飞速发展,数据爬取已成为获取网络数据的重要手段,特别是在每年的重要时刻,如往年12月18日,爬取网页数据的需求更是日益增长,本文将详细介绍如何使用小红书体进行网页数据爬取,并实时更新数据,帮助大家轻松应对数据获取的挑战。
准备工作
在进行网页数据爬取之前,我们需要做好以下准备工作:
1、选择合适的爬虫工具:如Scrapy、BeautifulSoup等;
2、学习爬虫基础知识:如HTTP请求、网页结构解析等;
3、确定目标网站:选择需要爬取数据的网站,并分析其网页结构。
往年12月18日爬取网页数据的技巧
1、抓取策略制定
在往年12月18日这个特殊时期,网站的数据更新速度非常快,我们需要制定高效的抓取策略,可以采用定时抓取的方式,设置爬虫在特定时间段进行数据爬取,以确保获取到最新数据。
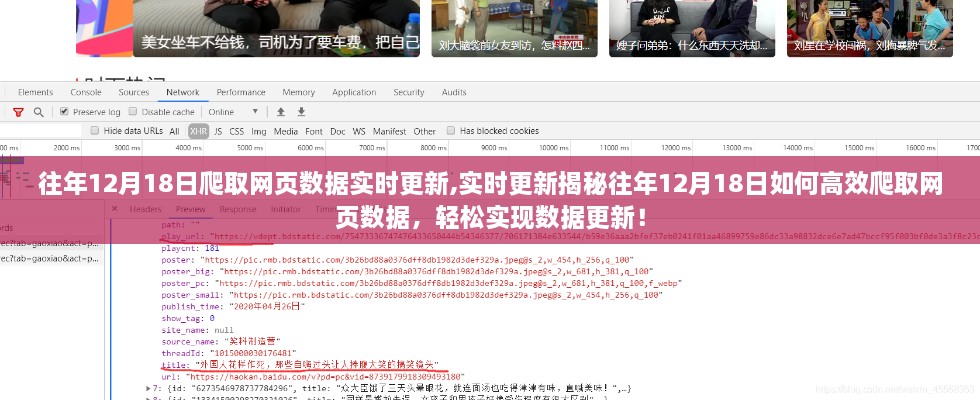
2、应对反爬虫机制
许多网站会设置反爬虫机制,以限制未经授权的访问和爬取,我们需要学会应对这些机制,如设置合理的请求头、使用代理IP等。
3、数据解析与存储
获取网页数据后,我们需要对其进行解析并存储,可以使用正则表达式、XPath或CSS选择器等方法进行数据提取,然后将数据存储到数据库或文件中,以便后续处理。
实时更新数据的实现方法
1、使用定时任务
通过设定定时任务,我们可以让爬虫在指定时间自动运行,实现数据的实时更新,可以使用Linux的Cron任务或Python的schedule库来设置定时任务。
2、数据校验与同步
为了确保数据的准确性和完整性,我们需要进行数据校验与同步,可以通过对比前后两次爬取的数据,找出差异并进行更新,还可以将数据同步到多个平台,以提高数据的可靠性和可用性。
五、案例分析:往年12月18日网页数据爬取的实战应用
以电商平台的商品信息爬取为例,我们可以使用Scrapy框架进行网页数据爬取,分析目标电商平台的网页结构,找到商品信息的定位元素,编写爬虫代码,实现商品信息的抓取、解析和存储,通过设定定时任务,我们可以实现商品信息的实时更新,还可以对数据进行校验与同步,确保数据的准确性和完整性。
注意事项与风险防范
1、遵守法律法规:在进行网页数据爬取时,要遵守相关法律法规,尊重网站的数据使用协议;
2、注意网站反爬虫策略的变化:网站的反爬虫策略可能会随时变化,我们需要密切关注并做出相应的调整;
3、数据备份与恢复:为了防止数据丢失或损坏,我们需要定期备份数据,并学会恢复数据的方法;
4、合理利用资源:避免过度爬取导致目标网站服务器压力过大,影响正常运营。
往年12月18日网页数据爬取是一项复杂而有趣的任务,通过掌握相关技巧和方法,我们可以轻松实现数据的实时更新,希望本文的介绍能对大家有所帮助,让大家在数据获取的过程中更加得心应手。
转载请注明来自嗅,本文标题:《揭秘往年12月18日高效爬取网页数据的秘诀,轻松实现实时更新!》
 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...